By @TheStackFox · February 2026
Grok Bot User Agent: xAI's Crawler Spoofs Its Identity
GPTBot shows up in every log. ClaudeBot is everywhere. GrokBot? I've never seen it. Not once. Nobody has.
View as SlidesI ran controlled tests and analyzed server logs. Grok's crawler never uses its documented user agents. It sends spoofed Chrome, Safari, and Go-http-client strings instead. That means robots.txt doesn't work against it. Behavioral detection does. Details below.
robots.txt is a convention, not a protocol. There's no enforcement mechanism. Scrapers have ignored it for decades. But Google, OpenAI, Anthropic: they all honor it. It only works when the bot operator cares about being seen as legitimate.
xAI doesn't.
GrokBot user agent strings (never seen in logs)
xAI documented three crawler names:
Cool. One problem: nobody has ever seen any of these in an actual HTTP request. Not in my logs. Not in anyone's logs. Not in any public server log analysis anyone has published.
A webmaster forum summed it up: "absolutely no examples of what a grok UA looks like."
When Grok fetches pages, it sends user agents likeGo-http-client/1.1,Chrome/139.0.0.0, andMozilla/5.0 (iPhone; CPU iPhone OS 18_0...). The word "Grok" never appears. Neither does "xAI."
AI training bots vs assistant bots
There are two kinds of AI bots. Training bots (GPTBot, ClaudeBot) crawl the web at scale for training data. Assistant bots (ChatGPT-User, Claude-User) fetch specific pages when you ask the AI to look something up.
Both types, for every other company, say who they are. The screenshots below show how that works. Then you'll see what Grok does instead.
How ChatGPT and Claude identify themselves
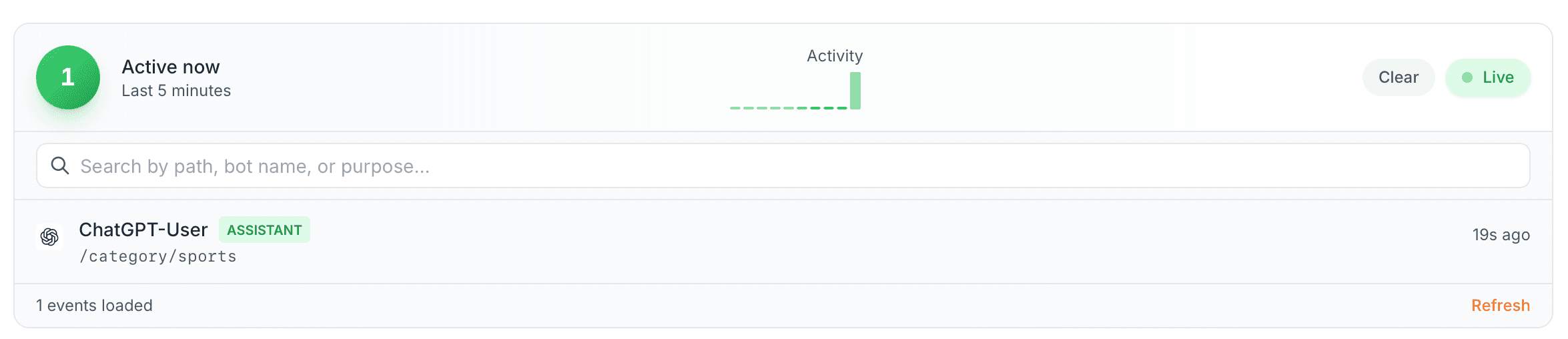
ChatGPT
One request. Labeled ChatGPT-User. You see it, you block it, you move on.
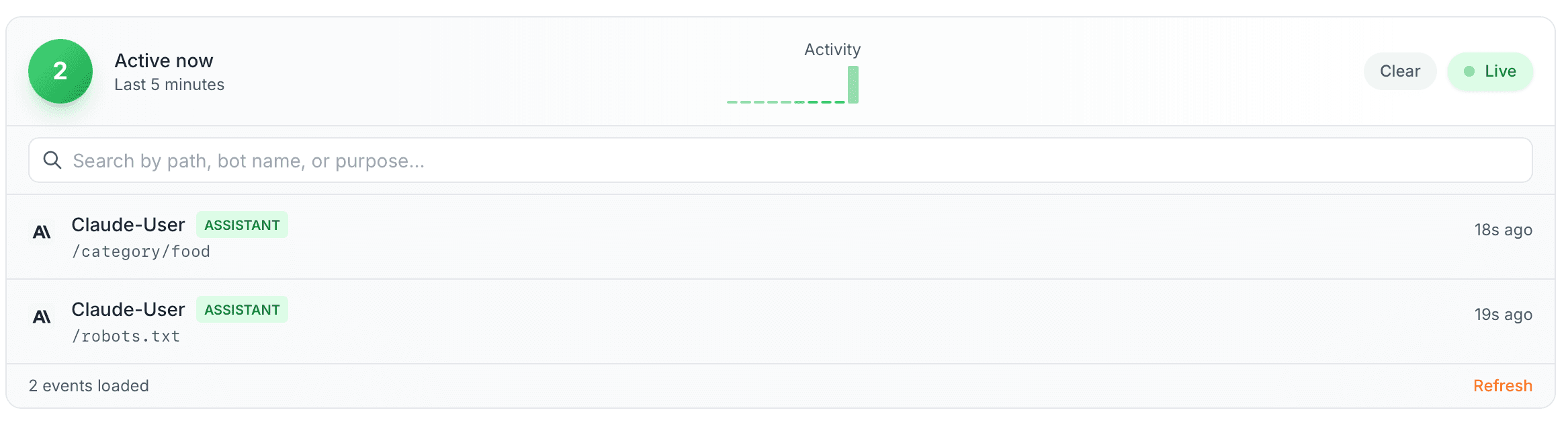
Claude
Even more polite. Before fetching the page you asked about, it requests /robots.txt to check if it's allowed. Then fetches the page. Both requests say Claude-User.
Grok
I asked Grok to look at a news site. Within one second, 30 requests hit the server.
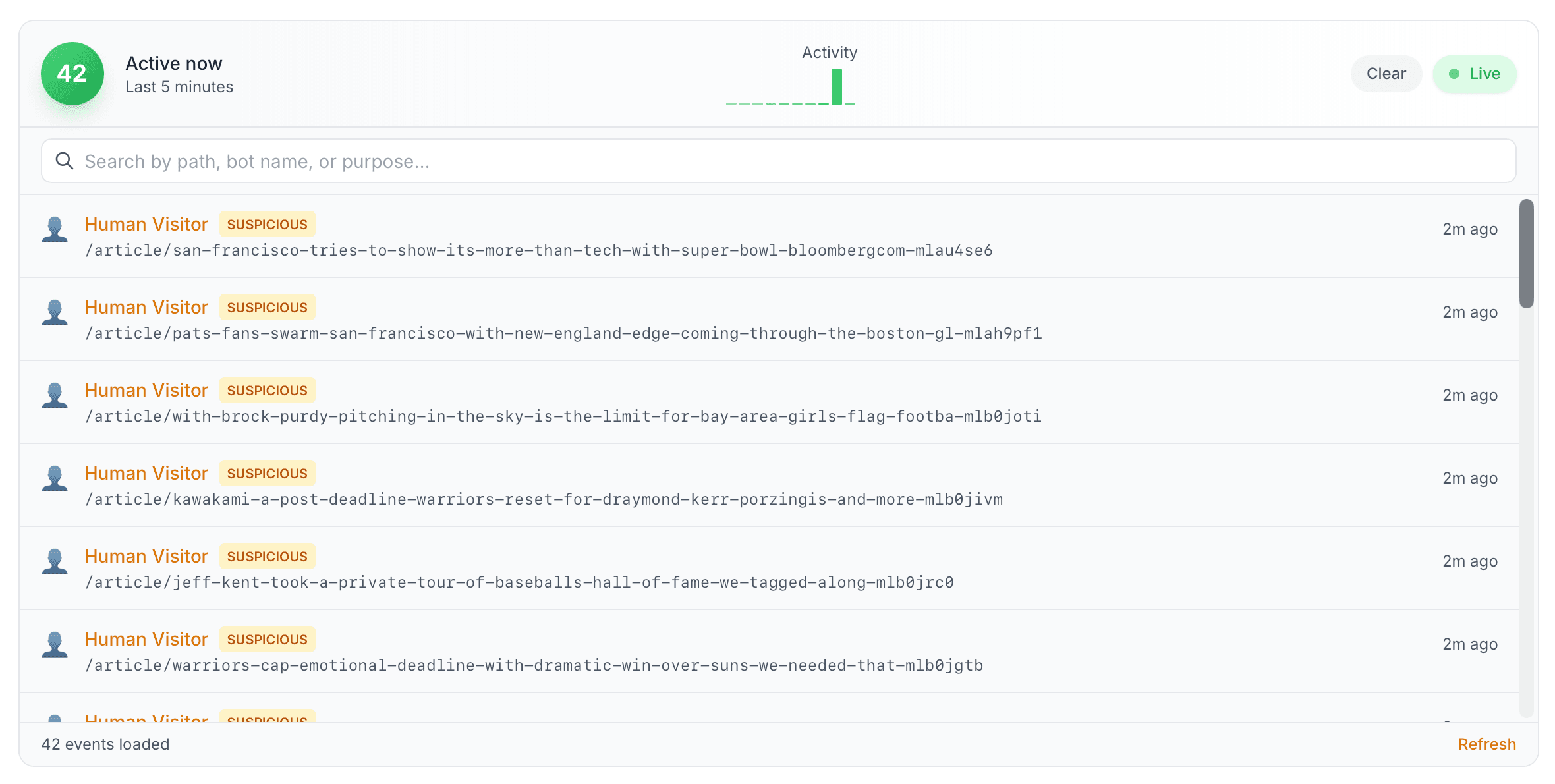
These got flagged automatically. The request velocity is inhuman, the crawl pattern is systematic, and the IPs are datacenters. Look at the detail view.
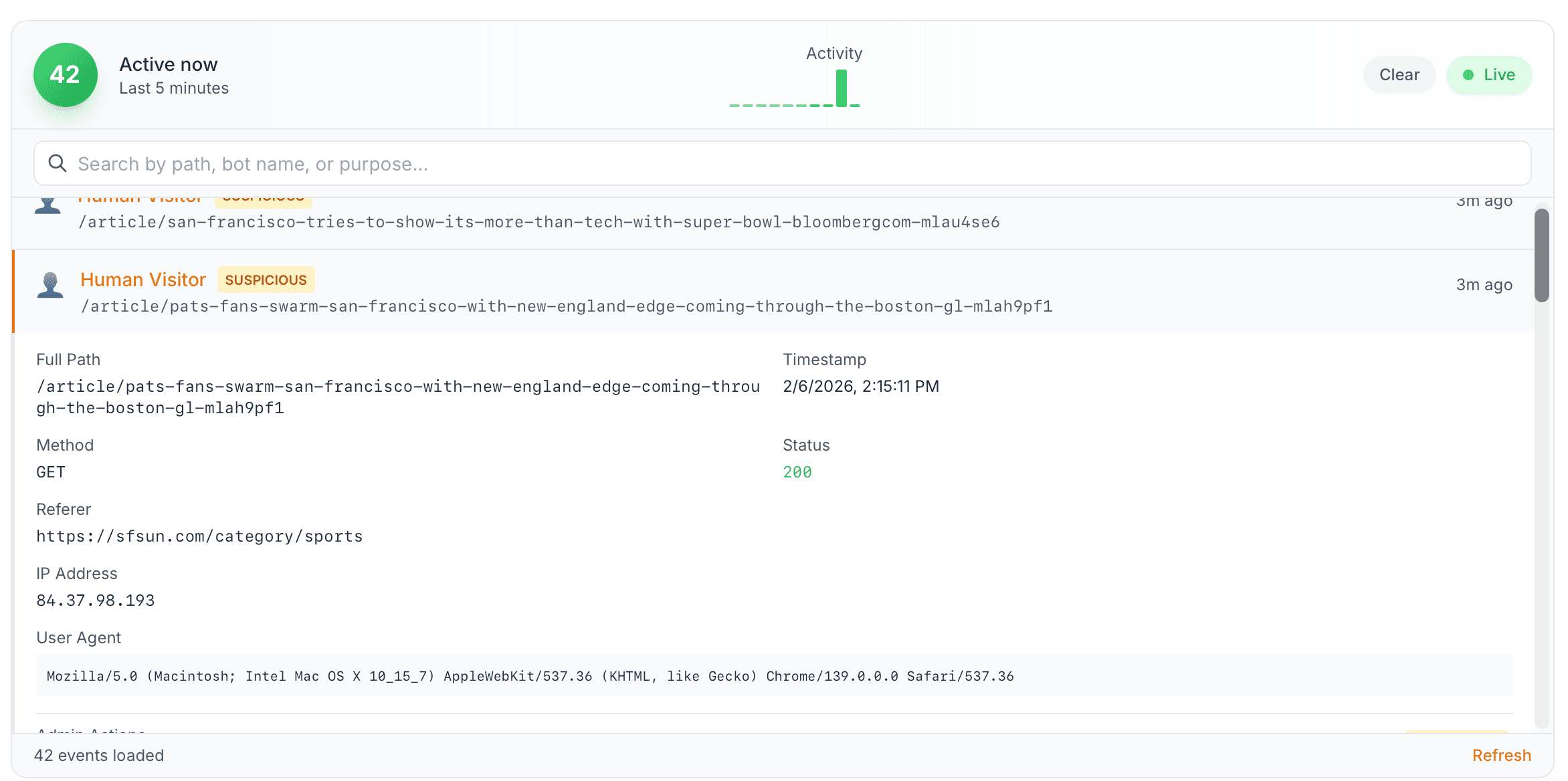
What Grok bot traffic looks like in server logs
The test below is from February 6, 2026. I've repeated it across different sites. Same pattern every time. Other people have reported the same thing, and Cloudflare has confirmed it independently.
I asked Grok to fetch content from a news site. 30 requests in under one second, from multiple IPs, all pretending to be Chrome.
| IP Address | Requests | Timespan | Behavior |
|---|---|---|---|
| 84.37.98.193 | 19 | ~1 second | Homepage + all 7 categories + 9 articles |
| 92.112.92.119 | 10 | ~0.3 seconds | 1 category + 9 articles |
Both IPs used the same user-agent:
Chrome 139 came out mid-2025. The current stable version is 146. Real browsers auto-update. A scraping tool pinned to a specific version string doesn't. And it shows.
The IPs
I traced both addresses. Neither is residential.
| IP | ASN | Organization | Type |
|---|---|---|---|
| 84.37.98.193 | AS9009 | M247 Europe SRL | Datacenter / VPN proxy |
| 92.112.92.119 | AS212238 | Datacamp Limited | Datacenter / proxy provider |
M247 is a big infrastructure provider whose IPs power VPN services like NordVPN and Surfshark. Datacamp Limited sells rotating proxies to web scrapers.
So: spoofed user agents, proxy networks, zero identification. xAI calls Grok's personality a "rebellious streak." In practice it just looks like a bot that doesn't want you to know it's there.
Grok admits it spoofs its user agent
I asked Grok directly: what is your user agent in practice?

Now, a caveat. LLMs make things up about themselves all the time. You can't take Grok's word about its own infrastructure any more than you'd trust ChatGPT to describe its own training data.
Except: Grok says it "almost never sends a clearly identifiable 'Grok' or 'xAI' user agent" and "intentionally spoofs common browser user agents to avoid being blocked." It lists which ones: iPhone Safari, Chrome on macOS, Go-http-client. The traffic data confirms all of it. The user agents match. The behavior matches.
Maybe Grok is confabulating. But it's confabulating exactly right.
How to identify Grok bot traffic
If Grok won't say who it is, how do you prove it's Grok? You set up a controlled experiment.
- Put up a page on a server you control. Turn on detailed logging.
- Ask Grok to fetch that URL.
- Compare when you sent the prompt to when requests hit your server.
- The burst of requests from multiple IPs, seconds after your prompt? That's Grok.
Why xAI doesn't identify its crawler
Why? Since 2023, a huge chunk of the web has updated robots.txt to block AI crawlers. xAI saw the same landscape as OpenAI and Anthropic. They just made a different choice.
Cloudflare put it plainly:
"xAI's bot, grok, does not self-identify at all, making it impossible for website operators to block it."
- Cloudflare, "To build a better Internet in the age of AI"
The logic writes itself. Grok needs live web data to work. If it identified itself, sites would block it. So it doesn't identify itself. Problem solved, if you're xAI.
AI bot transparency: who identifies and who doesn't
| Provider | Assistant bot | Checks robots.txt | Self-identifies |
|---|---|---|---|
| OpenAI | ChatGPT-User | Yes | Yes |
| Anthropic | Claude-User | Yes (first!) | Yes |
| Google-Extended | Yes | Yes | |
| xAI | Chrome/139 | No | No |
How to catch Grok bot with behavioral detection
You can catch it. Bots that hide their name can't hide their behavior. 19 pages in one second from a VPN proxy isn't someone reading the news.
- Burst patterns. Dozens of requests in under a second. No human browses like that.
- Datacenter IPs. M247, Datacamp, and other proxy providers. Not residential.
- Outdated browser versions. Chrome/139 when stable is 146.
- Systematic crawl order. Homepage, then categories, then articles. Like clockwork.
Any one of these could be adapted to. But the combination is a fingerprint. Burst velocity plus datacenter IP plus stale Chrome version plus systematic crawl order. That's hard to fake away without making the whole thing too slow to be useful.
Could xAI adapt? Sure. That means slowing down, buying residential IPs, updating headers, randomizing patterns. At some point the cost of hiding exceeds the cost of just identifying yourself. Not holding my breath. But the detection works today.
How to block Grok bot (and why robots.txt won't work)
If you've added User-agent: GrokBot to your robots.txt, I have bad news. You blocked a bot that doesn't exist.
The short version: detect bots by what they do, not what they claim to be.
Practical consequences
- robots.txt is useless against Grok. It never sends its documented user agents, so UA-based rules don't match. Ever.
- IP blocking is temporary. xAI routes through rotating proxy providers. Today's IPs are tomorrow's dead ends.
- Behavioral detection is the only reliable approach. Burst rate, UA version inconsistency, datacenter IP origin, systematic crawl order. These signals compound.
- The robots.txt model is broken. The whole thing assumes bots self-identify. When one doesn't, every site that relies on UA rules has a blind spot it can't see.
The bottom line
Grok's crawler acts like the scrapers it's supposed to be better than. No identification. Spoofed user agents. Proxy IPs. And when you ask it about this, it tells you. "Intentionally spoofs." Its words, not mine.
I track 95+ AI bots. GrokBot is listed because xAI documented it.
In all my traffic analysis, I've never seen it announce itself. Until that changes, blocking "GrokBot" in robots.txt is theater.
View the full AI bot database →If you're looking for Grok in your server logs, don't search for "Grok." Look for the burst of requests, the proxy IPs, the stale Chrome string. It's there. You can find it.
But xAI could save everyone the trouble by just saying who they are. Like everyone else does.
GrokBot robots.txt rules that don't work
Google "how to block Grok bot" and you'll find guides telling you to add this:
# This won't block Grok - they don't use these user agents User-agent: GrokBot Disallow: / User-agent: xAI-Grok Disallow: / User-agent: Grok-DeepSearch Disallow: /
These tokens exist in xAI's documentation but not in actual HTTP requests. You're blocking ghosts.
For comparison, these bots actually identify themselves:
# These actually work - these bots identify themselves User-agent: GPTBot Disallow: / User-agent: ChatGPT-User Disallow: / User-agent: ClaudeBot Disallow: / User-agent: Claude-User Disallow: / User-agent: Google-Extended Disallow: /
FAQ
What is Grok's user agent string?▼
Officially: GrokBot/1.0, xAI-Grok/1.0, and Grok-DeepSearch/1.0. In practice: outdated Chrome versions (Chrome/139 when stable is 146), iPhone Safari strings, and Go-http-client/1.1. Grok itself confirmed this when asked.
Does Grok respect robots.txt?▼
No. It doesn't identify itself with its documented user agents, so robots.txt rules don't match. Compare to Claude, which checks robots.txt before every fetch.
How can I actually block Grok?▼
robots.txt and user-agent rules won't work. Behavioral detection does: burst patterns from datacenter IPs, outdated browser versions, impossible request speeds. The signals are there if you know what to look for.
What IPs does Grok use?▼
xAI doesn't publish IP ranges. I've observed traffic from M247 Europe SRL (AS9009) and Datacamp Limited (AS212238), both proxy/VPN providers. They rotate, so blocking specific IPs is a temporary fix.
Sources
- • StackFox: Live traffic analysis and IP investigation, February 2026
- • Cloudflare: "To build a better Internet in the age of AI" (December 2025)
- • DataDome: "The Great Masquerade: How AI Agents Are Spoofing Their Way In" (December 2025)
- • WebmasterWorld: "Where is grok bot / xAI?"